Annotate
Train
Automate
aivisiontrainer.com



As humans, we can easily interpret a specific object in an image or a video but for computers it is not that easy task to complete. We need to develop ways to give computers the ability to see the world as we humans do. Computer vision is a subdiscipline of computer science that deals with it. Specifically, object detection is a computer vision technique for locating instances of objects in images or videos. Modern object detection techniques usually take advantage of machine learning and deep learning. In this blog post, we’ll look at how a simple object detection pipeline works, common object detection models, and what AIVISIONTRAINER (AVT) brings to the table for your object detection tasks.
Object Detection Pipeline
Each object detection pipeline starts with deciding on which objects we need to detect in an image or a video. After that, the pipeline includes the following steps:
- Create a dataset which contains at least one instance of the object we want to detect. To create a dataset, you may use public datasets created by other people or you can collect your own data by recording videos or taking photos
- Label your initial dataset which means using tools to annotate each object of interest in your dataset (We’ll talk about annotation later)
- Decide on which object detection model you will use for your task (We’ll explain models later)
- Creating annotation files compatible with your selected model for dataset you labelled at Step 2 (Will be explained in detail at another blog post)
- If required, apply a group preprocessing operations to improve the visual quality of your dataset (Will be explained in detail at another blog post)
- If required, apply a group of operations called augmentation to increase the number of samples in your dataset (Will be explained in detail at another blog post)
- Train your model and getting the trained model weights which is provided as an output file called as weights file
- Use your weights file, and some programming tools to create your custom object detection application that runs on a computer or an embedded system
Even though some specific object detection tasks may require some specific steps, a generalized object detection pipeline must follow steps like we explained above.
Data Annotation and Bounding Boxes
Data annotation involves labeling each sample in your data set and creating annotation files for data set training. To label your data, you need certain tools that allow you to draw bounding boxes onto your image or video frames which brings the question of what a bounding box is.
A bounding box is a rectangular shape that surrounds the object of interest in an image (Figure 1).

To complete the data annotation step, you need a digital tool that allows you to draw bounding boxes assigned to each object of interest (Figure 2) and gives you the coordinates of those boxes. The coordinates of these boxes are combined with the names of the objects, and this information is written into a text file called a label file or annotation file (Figure 3) (Will be explained in detail at another blog post).


In application, there are formats for representing labels and objects in the label/annotation files. YOLO format is one of the well-known and most used (Figure 4).
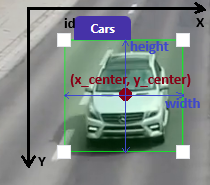
Typical YOLO format is given below.
object-of-interest x-center y-center
width height
object-of-interest: A unique id given to
object we want to detect (Starts from 0
and increase by 1 for each unique
object)
x-center: x coordinate (In range of [0,
1]) of the center of a bounding box
(Normalized by width of the image)
y-center: y coordinate (In range of [0,
1]) of the center of a bounding box
(Normalized by height of the image)
width: Width of a bounding box (In range
of [0, 1], Normalized by width of the
image)
height: Height of a bounding box (In
range of [0, 1], Normalized by height of
the image)
Currently our product; AVT provides all the tools you need to annotate your data. You can assign data set to a team of your choice, they can label your data set with the tools we have, and you can monitor all the annotation process with a single click!
Object Detection Models
Object detection models are deep learning models that are especially trained for object detection tasks. Currently, popular models are
- YOLO (You Only Look Once)
- Detectron2
- EfficientDet
- SSD (Single Shot MultiBox Detector)
- Faster R-CNN
- Mask R-CNN
Selection of a model depends on the requirements of specific object detection task. Some models are built for detection efficiency, some are built for training time efficiency, and some are at the middle of them. Whichever you choose, it is certain that you need to have a certain amount of computational power to benefit from these models. Most of the computers we use at our homes are not strong enough to undermine such tasks.
Our product; AVT provides required tools for you to use those models without knowing the things going under the hood or needing a high-end computer. Currently we bring you YOLOv4 and YOLOv5 (addition of other models are on our agenda) models for your object detection tasks.
What does AVT brings to the table?
AVT intends to bring all the tools you require to complete your object detection pipeline in a simple web browser-based application. All you require is just an internet connection and a web browser. We will take care of all other complex things for you.
In detail, AVT provides easy to use tools for:
- 1.Creating separate workspaces and projects
- Managing people in your workspaces and projects
- Uploading your data set via selecting it from your own data storage or YouTube
- Distributing your data labeling workload among project members
- Labeling your data set for creating label/annotation files
- Monitoring data labeling performance per project member
- Preprocessing your data set for improved visual quality
- Augmenting your data set for increased data set size
- Using state of the art object detection models for training of your data set
- Getting results of the training in form of common files
If you choose AVT, you will be able to
complete your object detection pipeline
in an all-in-one platform!
Are you ready to start? CLICK HERE!